- May 27, 2026
- Artificial Intelligence
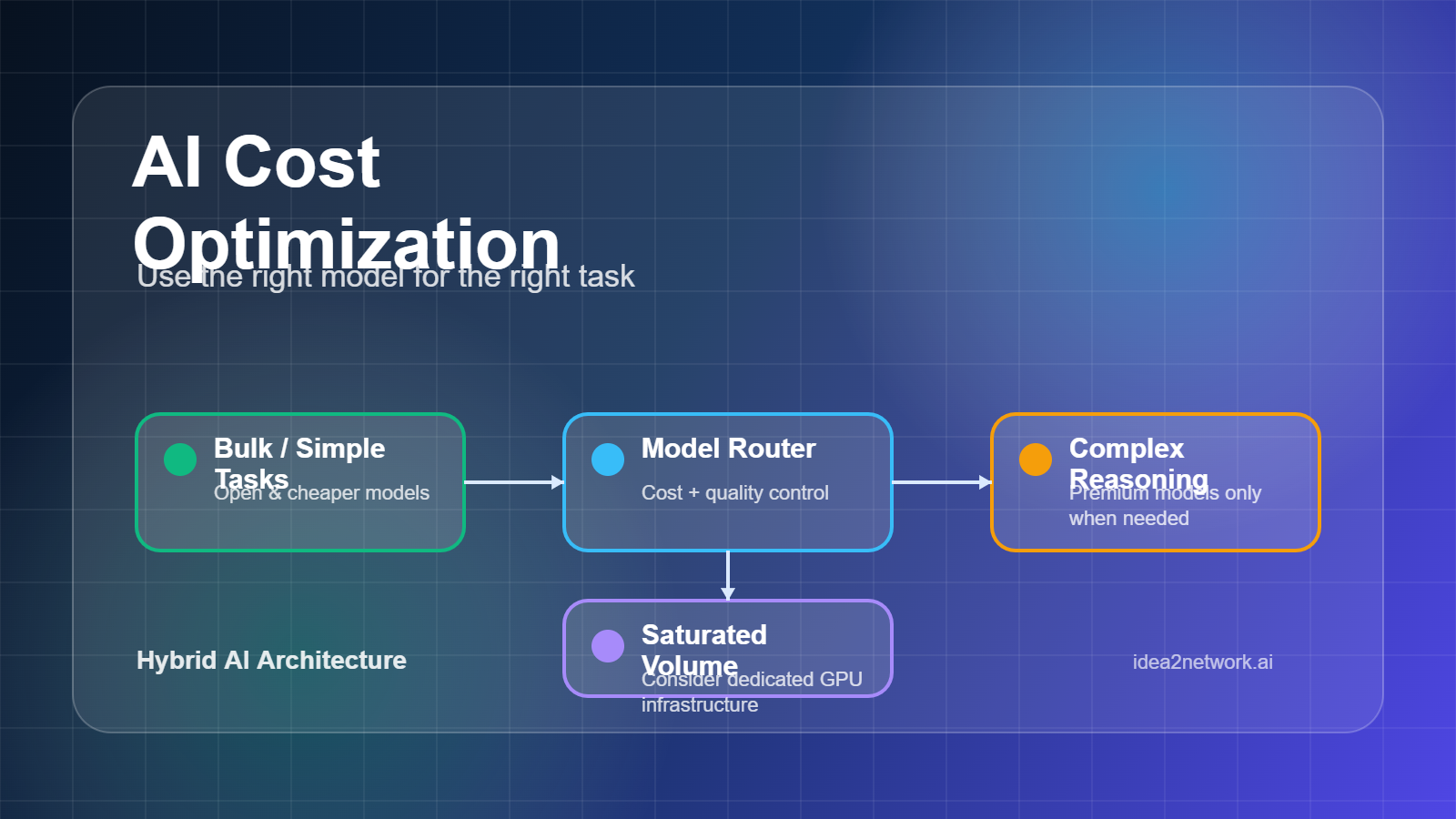
AI cost optimisation is not about replacing every large language model (LLM) with a small language model (SLM). It is about using the right model for the right workload — and building an architecture that scales intelligently without burning cloud budget unnecessarily. At Idea2Network, this principle drives how we architect enterprise AI solutions for clients like BiteMate.
The Biggest Cost Mistake in AI Architecture
One of the most common and costly mistakes in Agentic AI architecture is using powerful models like GPT-4.1 or GPT-5.1 for every single task. Not every workflow requires deep reasoning, complex inference, or advanced language understanding. Many tasks — such as data extraction, classification, tagging, summarisation, and lightweight preprocessing — can be handled effectively by smaller, more efficient models at a fraction of the cost.
What Is a Hybrid Model Strategy?
A hybrid model strategy means selecting the most appropriate AI model based on the complexity of each specific task. Rather than defaulting to the most powerful (and most expensive) model for everything, you match workload requirements to model capabilities. This is the foundation of scalable, cost-effective enterprise AI.
Use Larger LLMs For:
- Complex reasoning and multi-step problem solving
- Personalised recommendations requiring deep contextual understanding
- Agentic AI workflows with autonomous decision-making
- Chatbot intelligence for nuanced, human-like conversations
Use Smaller Models or SLMs For:
- Menu parsing and structured data extraction
- Data extraction from documents and forms
- Tagging and classification at scale
- Simple preprocessing tasks and lightweight transformations
Why This Matters Most in Agentic AI
This hybrid approach is especially critical in Agentic AI systems, where token usage can escalate rapidly. A single user request may trigger multiple prompts, carry extensive context history, and invoke repeated model calls across agents. Without deliberate cost management, token costs compound quickly across thousands of daily interactions.
Key Optimisation Levers for AI Cost Control
The real optimisation in AI architecture comes from a combination of smart engineering decisions and the right tooling. At Idea2Network, we apply the following strategies across client deployments:
- Reducing prompt size — strip unnecessary context before every model call
- Avoiding repeated full context — pass only what the model needs for each step
- Limiting unnecessary conversation history — use sliding windows or summarisation
- Using Redis or semantic caching — cache common responses to avoid redundant API calls
- Tracking token usage through Azure Monitor and App Insights — gain full visibility into model consumption patterns
- Using Azure API Management (APIM) — for routing, throttling, rate limiting, and governance across AI endpoints
- Exploring Microsoft Foundry Model Router — to dynamically select the right model for each request based on task complexity and cost
One Important Point: SLMs Are Not Always Cheaper
It is tempting to assume that smaller models always mean lower costs. But the reality is more nuanced. Azure OpenAI is primarily token-based, meaning you pay for what you use with no infrastructure overhead. Self-hosted SLMs, on the other hand, bring significant infrastructure costs — including GPU virtual machines, AKS nodes, persistent storage, monitoring agents, and ongoing maintenance.
- For low or bursty workloads — Azure OpenAI is often still the cheaper and simpler option
- For high-volume repetitive workloads — self-hosted SLMs can become significantly more cost-effective over time
Understanding this trade-off is essential before committing to any self-hosting strategy. This is why our team at Idea2Network always conducts a workload analysis before recommending a model deployment approach.
BiteMate: A Practical Hybrid Azure AI Architecture
For BiteMate, the practical path forward is not a binary LLM vs SLM decision. It is a hybrid Azure AI architecture designed for intelligent, cost-efficient scale:
- Azure OpenAI — powering intelligence, reasoning, and personalised recommendations
- Smaller models — handling repetitive processing tasks like menu parsing, tagging, and extraction
- Caching and monitoring — Redis caching and Azure Monitor for cost visibility and control
- Model routing — smarter workload distribution using Microsoft Foundry and MCP-aware routing to match each request to the optimal model
That is how we build scalable Agentic AI without burning cloud budget unnecessarily — combining the power of large models where it matters with the efficiency of smaller models where it counts.
Conclusion: Intelligence Is Knowing When to Use Which Model
AI cost optimisation is not a one-time decision. It is an architectural discipline. The organisations that win with AI are not those who deploy the biggest models — they are those who deploy the right models with the right guardrails, monitoring, and routing in place. If you are building or scaling an Agentic AI architecture, reach out to the team at Idea2Network — we help enterprises build AI systems that are intelligent, secure, and cost-effective from day one.
#AgenticAI #AzureOpenAI #SLM #LLM #MicrosoftFoundry #AzureAI #PhiModels #SemanticCaching #APIM #AIArchitecture #CostOptimization #EnterpriseAI #MCP #idea2networkai #BiteMate



